joel sommers
director, division of natural sciences and mathematics
professor, department of computer science
colgate university
hamilton, ny 13346
jsommers///at//colgate/dot/edu
+1 315 228 7587
github: jsommers
pgp fingerprint: B200 47BE 8D65 B622 0B24 8099 27D6 38F3 A545 719B
Automating Active Measurement Metadata Collection and Analysis
Empirical research in the Internet is fraught with challenges. Perhaps chief among these is that local environmental conditions (e.g., CPU load or network load) can introduce unexpected bias or artifacts that can lead to poor measurement quality and erroneous conclusions. The goal of this project is to investigate and develop new methods for automatic collection of metadata and calibration data for network measurement experiments and to create algorithms for detecting and potentially correcting for bias in the measurement data. Collection of metadata for measurement methods that target all layers of the networking protocol stack will be addressed through this project, such as latency (ping), routing (traceroute), TCP throughput, and application-level performance measurements.
The tools developed through this project will be deployed for extensive experimentation in a campus network as well in a widely-used platform in order to evaluate and improve their performance and operational capabilities. The tools will be made openly available to the research community and will be designed for lightweight operation on a variety of target computing platforms and thus be broadly deployable. Best-practices documentation will be created and published in order to facilitate optimal use of the tools and algorithms developed through our research.
This page exists to document progress toward the goals of this project.
Acknowledgment
I gratefully acknowledge support from the National Science Foundation for this project (grant number 1814537, titled “NeTS: Small: RUI: Automating Active Measurement Metadata Collection and Analysis “). All opinions and findings are those of the author and do not necessarily reflect the views of the NSF.
Posts
- SoMeta updates and current work (03 Aug 2021)
- ELF: eBPF telemetry framework (30 Jul 2021)
- Internet latency is more 'constant' than it was 20 years ago (23 Jul 2021)
- Summer 2020 activities (04 Sep 2020)
- SoMeta tool reborn in Go (19 Jul 2019)
- Metadata collection in other sciences (21 Dec 2018)
SoMeta updates and current work
03 Aug 2021
SoMeta has been enhanced to provide a new configuration mechanism through a simple yaml configuration. Configuring through a yaml file makes SoMeta more easily automated since config templates can be created and filled in as needed by a variety of automation tools. Internally, we’ve completely moved to using SoMeta in this arrangement. An example config file is provided in SoMeta’s Github repo.
A minor update to the user-contributed ss monitor to enable user-specified command-line options for the Linux /bin/ss tool instead of hard-coding them in the binary. The ss monitor is on its way to obsolescence anyway, as have also created a new cmdlinetool monitor that generalizes (and thus subsumes) the functionality of the ss monitor. Moreover, the ss monitor was Linux-only, but the new command-line tool monitor does not have any restriction regarding build OS.
Building on what we’ve learned with SoMeta and ELF, we are pursuing three inter-related goals: (1) examining throughput measurement methods and their strengths and weaknesses, (2) examining a new model-based latency filtering technique based on the Kalman filter and a fluid queue model, and (3) examining noise introduced by rate limiting and “slow” host processing on ICMP time exceeded responses from intermediate routers. Given our experiences with SoMeta and ELF, we are optimistic about gaining new insights into the behavior and performance of throughput measurement tools such as MLab’s NDT, Ookla Speedtest, Netflix’s FAST and perhaps others (e.g., librespeed). Other researchers have examined differences between throughput measurement tools, but not alongside metadata collection methods like those we have developed. We will be doing this study while using and enhancing SoMeta and ELF over the coming year.
ELF: eBPF telemetry framework
30 Jul 2021
The SoMeta tool as originally developed in this project was designed for certain types of measurement processes, in particular rather low-rate, periodic network measurements. Some network measurement processes, e.g., throughput measurement methods, were not a very good fit for our approach. For example, with throughput measurement, the packet streams may be emitted to multiple endpoints (e.g., as is done with Netflix’s FAST), or there may be multiple packet streams emitted in parallel (many tools do this), and those streams may be subject to in-network load balancing. So if we want to know which (layer 3) network paths were traversed by the throughput measurement packet streams, the original SoMeta tool couldn’t help. It also couldn’t help if we wanted to try to understand whether the throughput limitation was due to in-network congestion or due to an end-host constraint. These issues are incredibly important in efforts to characterize broadband deployments (e.g., the US FCC’s Measuring Broadband America) and for customers to ensure that they are getting what they pay for, as well as for holding service providers to account for the actual service they deliver.
In a paper published in the IFIP Traffic Measurements and Analysis Conference we describe a tool called ELF (eBPF telemetry framework) which tremendously extends the metadata collection methods we’ve developed. ELF is an in-band network measurement tool implemented using the extended Berkeley Packet Filter (eBPF). The basic operation of ELF is to monitor packet streams with particular (IPv4 or IPv6) destinations, and periodically inject clones of application packets, but with the TTL/hop count modified such that the packet with “expire” along the path. The expiring packet typically triggers an intermediate router to generate an ICMP time exceeded message. Round-trip latency measures between the end host and intermediate routers can then be computed between the ICMP time exceeded message and the probe that triggered it. There are other tools that have explored in-band measurement, but ELF is distinctive in that (1) it is implemented using eBPF and thus resides in-kernel, making it much more efficient than other tools, (2) incoming ICMP time exceeded messages can be dropped prior to their entry into the host TCP/IP stack, reducing load on the end host, (3) and there are several hooks for extending the functionality of ELF, for those intrepid persons who want to do so.
In our paper, we examine the performance of ELF in a laboratory setting and show that it does not suffer from problems that plague other tools that are based on the standard libpcap library for packet reception and injection. Moreover, we used ELF in a wide-area internet study to illustrate its potential for diagnosing the causes behind observed application performance. In particular, we used the Measurement Lab’s NDT tool to generate TCP flows across the wide-area internet and used ELF to instrument those flows. The ELF measurements reveal in-network queuing behaviors at different intermediate routers, the impact of load balancing (which may not give equal performance across load-balanced paths), and impacts of mid-flow route changes.
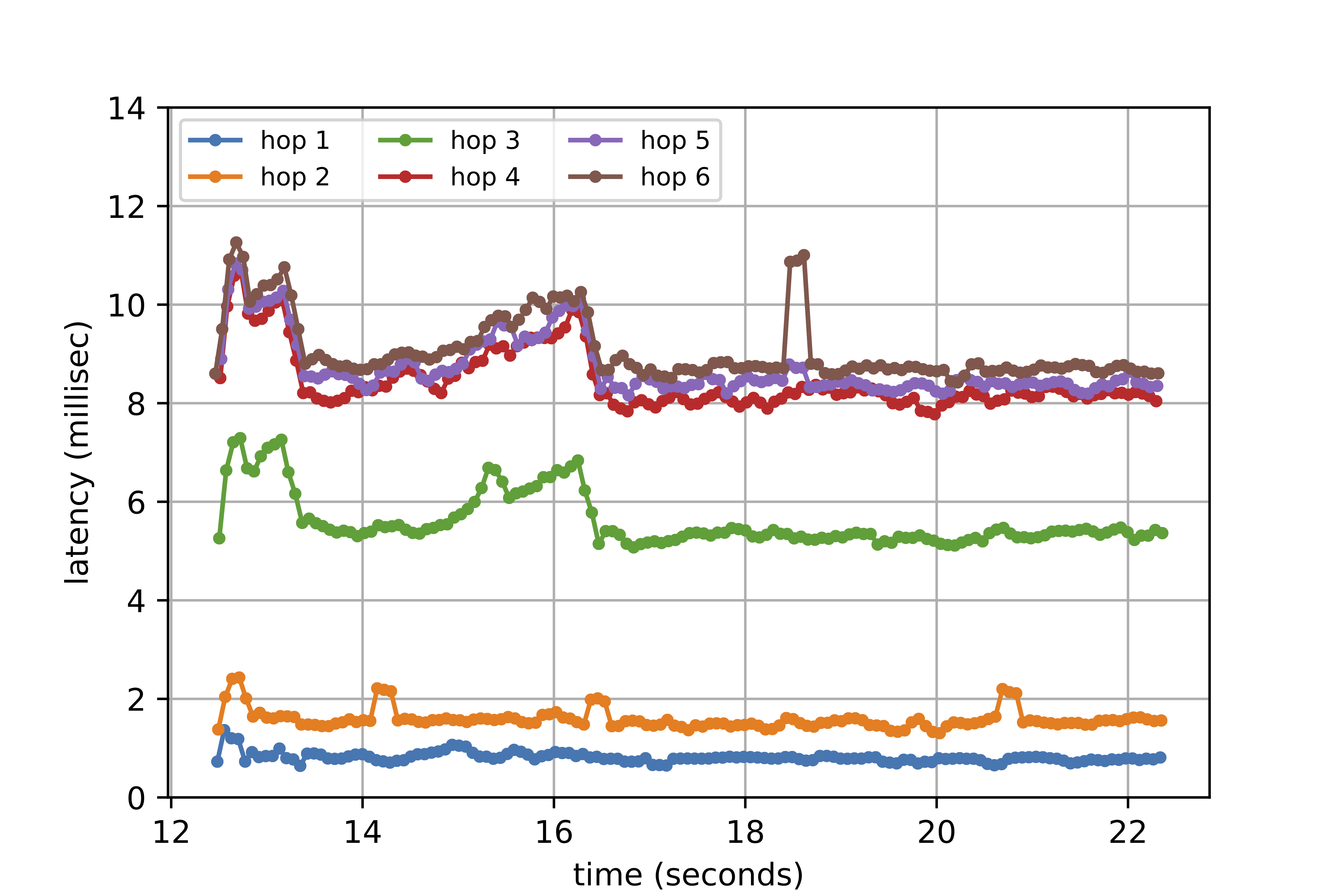
An example plot generated from ELF measurements is shown below. This is constructed from a NDT test between a host at Colgate and an MLab server in New York City. Latency measures for the first two hops are from devices within Colgate’s network; hop 3 is a provider network. Leading up to t=16s (and a bit beyond) we can see the effect of a queue building at hop 3 — notice that earlier hops have a “flat” latency profile, but hops beyond 3 are subject to increased delays at hop 3. Although the NDT has limitations that can cause it not to accurately measurement throughput, it is clearly creating enough pressure on the network to create congestion. With a throughput measurement tool, this is generally what we want to see! Not shown, and somewhat less exciting, are plots that show that NDT is limited by TCP’s receive window or some other constraint, which cause it to underestimate throughput.
We also observe some somewhat noisy behavior in the latency measurements (these are the “raw” latency measurements). In our ongoing work, we are examining methods for filtering these data points. We are also focusing squarely on the throughput measurement domain and how we can utilize ELF and SoMeta to help us understand the reasons behind a throughput measurement result.
Our code for ELF is available on Github.
Internet latency is more ‘constant’ than it was 20 years ago
23 Jul 2021
As part of this project, four Colgate undergraduate students worked with me to investigate how “constant” end-to-end internet latencies are today. The primary goal of this study was to compare latency characteristics measured today with those measured by Zhang et al. in the 2000-2001 study published at the Internet Measurement Workshop in 2001 “On the constancy of Internet path properties”. An additional goal of our study, intimately related to this project, was to investigate methods for identifying and filtering out noisy or otherwise “bad” latency measurements.
Our overall findings from the study are that internet latency is quite a bit more constant and stable than it was 20 years ago, and furthermore that stability appears to have improved steadily over the past 5 years, pandemic network effects notwithstanding. Our paper, published at the IFIP Traffic Measurement and Analysis Conference (September 2021) details other findings from the study.
In our study, we used data collected by the RIPE Atlas project. In particular, we used built-in ping measurements within a full mesh of about 120 Atlas anchors, each of which was dual-stack IPv4/IPv6. An interesting set of built-in measurements collected by Atlas anchors and probes is the latency measurements to the first and second hops. These measurements have some similarity to those that can be collected by our tool SoMeta in our initial study published in IMC 2017. In that paper, we used those measurements (along with other host-based measures like CPU utilization and memory pressure) to assess whether measurements along a path were likely to reflect network conditions outside the local network, or whether they were likely to be biased in some way.
In extensive study of first-hop latency measurements collected by RIPE Atlas anchors, we concluded that those measurements may be useful in some contexts for filtering out noisy or biased data, but must be used with extreme caution. The key problem is that, as has been studied in prior work (e.g., Govindan and Paxson, “Estimating Router ICMP Generation Delays”, PAM 2002), ICMP time exceeded responses are often subject to router-internal generation delays, resulting in poor latency measurements. We observed this for the vast majority of first-hop latency measures we investigated for the collection of Atlas anchor hosts we used. This problem is particularly acute with lower-end or edge routers and switches. Linux networking stacks often do not exhibit these anomalies; there are a variety of sysctl configuration parameters that specify how ICMP responses may be rate limited, etc., but if a response is not subject to these rate limits it is often returned with minimal additional delay. Thus, the conclusion we came to is that if the first-hop router is known to be a Linux host or to exhibit (in general) little additional delay when generating ICMP time exceeded messages, the approach indicated in our earlier work (IMC 2017) is reasonable. That is, one can collect a sufficiently large sample of first-hop delay measurements to establish a baseline distribution, and then use a Kolmogorov-Smirnov 2-sample test — comparing newly collected first-hop measurements with the baseline — to determine whether there is likely to be some bias in the measurement collection. If no such information about the first-hop router can be established, this method should not be used. In our ongoing work, we are continuing to examine these issues using a model-based approach based on Kalman filtering and a fluid queuing model.
Summer 2020 activities
04 Sep 2020
This past year has been … strange. The pandemic has slowed the project, but there has been some good progress nonetheless. I am very excited about some specific areas of work, but details will have to wait until papers are accepted.
Some highlights from the past year:
-
The Golang rewrite of SoMeta was enhanced further, and we have started to deploy on some resource-constrained devices. Some of the deployment and in situ experimentation has had to be put on hold and/or delayed because of the pandemic.
-
Students working with me have been investigating some filtering methods on RIPE Atlas data in the context of reproducing aspects of the 2001 Internet Measurement Workshop paper “On the constancy of Internet path properties” by Zhang et al. I’m really happy about what the students have been able to accomplish and hope to say more about the project in a future post.
-
Some significant enhancements to the Switchyard platform for education projects. Most importantly, IPv6 projects are now fully supported, which has been a long time coming.
Again, lots of details will have to remain untold until papers see the light of day…
SoMeta tool reborn in Go
19 Jul 2019
The basis for this project was a study carried out in 2017, described in a paper published at the Internet Measurement Conference that year. That paper, Automatic metadata generation for active measurement, described a tool called SoMeta that was designed to collected metadata about the local compute and network environment as a network measurement tool runs in order to determine whether there was any unexpected interference that could have disrupted the measurement. The paper described a set of experiments we carried out to assess the effectiveness of the tool to capture the sort of metadata that might help to understand the quality of a measurement (or set of measurements), as well as the overhead of the tool, i.e., how much computational resources it needed to do its job.
In an initial deployment of the original tool on a Raspberry Pi 2 on one of nodes in CAIDA’s Archipelago system, we discovered that the tool used too much CPU on the device. (Experiments in our paper were done with slightly higher-powered Raspberry Pi’s and other devices.)
We undertook a complete rewrite of the tool over the past year, converting it from Python to Go. An initial version of the tool is now available on Github and we are currently carrying out new experiments to assess its overhead in comparison with the first version. Not surprisingly, initial measurements indicate that the new version is much more compute-efficient.
The code and some initial documentation for the new version of SoMeta is, again, available on Github. No more updates will be made to the original Python version, but it will still continue to be available.
Metadata collection in other sciences
21 Dec 2018
A question that was raised in the panel reviews for this project—and which has come up in other discussions I’ve been part of—is, what do other sciences do about metadata collection? In particular, what could computer scientists learn from gaining a better understanding about what other researchers have done in prior work?
A challenge of identifying relevant comparable work is that while quite a number of papers discuss reproducibility of experiments and many of those papers discuss capturing experiment metadata, in the majority of cases static forms of metadata are considered rather than more dynamic forms which are the main focus of our work. For example, static metadata might be considered as contextual details of an experiment that do not change as an experiment evolves such as software versions, system configuration details and the like. Dynamic metadata could be aspects such as CPU usage of experiment devices during an experiment, ambient temperature during an experiment, etc.
Below is a selection of papers identified by one of my undergraduate student researchers, Nhiem Ngo, class of 2021. The papers identified below are almost certainly not comprehensive of efforts to collect dynamic forms of experiment metadata. They are drawn from other sciences and from other areas of computer science. The bottom line when analyzing the literature for related efforts to collect dynamic metadata is that methods, in general, are highly discipline and experiment-specific. That is, there are some methods that admit to some generality in application, but most methods are very particularly-suited to the given experiment environment and requirements. Nevertheless, it is instructive to learn what others have done and how they might inform our ongoing work.
Special thanks to Nhiem for identifying these papers and writing some notes about their relevance!
- D. Bornigen, Y.-S. Moon, G. Rahnavard, L. Waldron, L. McIver, A. Shafquat, E.A. Franzosa, L. Miropolsky, C. Sweeney, X.C. Morgan, W.S. Garrett, and Curtis Huttenhower. A reproducible approach to high-throughput biological data acquisition and integration. PeerJ, 3:e791, March 2015.
This paper deals largely with more static forms of metadata capture and automation in the context of experiments with biological data. It notes that automated methods for metadata capture regarding multiple data sources that might be used in experiments were not widely used or available at the time of the writing of the paper. The paper also acknowledges the challenges in gathering and analysing metadata: “… retrieving, standardizing, and curating such data is nontrivial, time-consuming, and error-prone. Integration of heterogeneous data can be an even more onerous process.”
- F. Chirigati, D. Shasha, and J. Freire.
ReproZip: Using Provenance to Support Computational Reproducibility.
The tool mentioned in this (very cool!) paper has a number of similaries to the SoMeta tool developed in our work. It is designed to capture operating system calls as a computational tool runs, enabling “detailed provenance of existing experiments, including data dependencies, libraries used, and configuration parameters”. These data are collected to aid in reproducing an experiment at some later time, possibly by different researchers. The focus is largely, still, on static types of metadata, but clearly relates to our work.
- A.~Davison. Automated Capture of Experiment Context for Easier Reproducibility in Computational Research. Computing in Science Engineering, 14(4):48–56, July 2012.
This paper shares our current research objective. It mentions the need to capture “experiment context”—similar to the notion in our work—to aid in reproducibility, and identifies two requirements to make computational work more reproducible: (i) reduce the sensitivity of the results to the precise details of the code and environment; (ii) automate the process of capturing the code and environment in every detail. Again, the metadata focus is more on the static aspects of the experiment environment and configuration; the author discusses the use of VMs and containers for taking snapshots of code and context. It also discusses use of devops-type tools such as Puppet and Chef to automate as much as can be automated in the experiment setting. Finally, it discussed a tool called called Sumatra which is designed to collect experiment context such as configuration details, as well as new files that may have been created as an experiment ran. (Notice the similarity with the ReproZip tool described above.)
- R. Mahmood, S.A. Foster, and D. Logan. The GeoProfile metadata, exposure of instruments, and measurement bias in climatic record revisited. International Journal of Climatology, 26(8):1091–1124, June 2006.
This paper specifically mention measurement tools and the importance of measuring metadata associated with measurement tools (in this case, weather stations). The authors claim that in the area of climatology, weather station metadata plays a critical role in data analysis and prediction, yet “current procedures of metadata collection are insufficient for these purposes”. The paper describes a broad set of weather and environment-related metadata that the authors claim should be captured.
This paper is one of the most relevant to our work since its focus is almost entirely on collection of dynamic forms of metadata, i.e., environmental or contextual parameters that change as an experiment runs (or as measurements are collected).
This paper was published in 2006, which is relatively recent. - G. Nilsson. On the measurement of evaporative water loss : methods and clinical applications. PhD thesis, Linköping University, Department of Biomedical Engineering. Linköping University, The Institute of Technology. Linköping University, Department of Biomedicine and Surgery, Oncology. Linköping University, Faculty of Health Sciences. 1977.
Although this is a relatively old paper, it is one of the few concerning biological experiment metadata that Nhiem was able to identify. It focuses on one specific aspect: how air humidity affects the evaporation rates of water on people’s skin. It relates clearly to our work in that collection of air humidity metadata must be done as an experiment evolves in order to do any proper analysis.
- L. Zehl, F. Jaillet, A. Stoewer, J. Grewe, A. Sobolev, T. Wachtler, T.G. Brochier, A. Riehle, M. Denker, and S. Grün. Handling Metadata in a Neurophysiology Laboratory.
Frontiers in Neuroinformatics, 10, July 2016.
This paper, in the area of neurophysiological research, discusses how “ the complexity of experiments, the highly specialized analysis workflows and a lack of knowledge on how to make use of supporting software tools often overburden researchers to perform such a detailed documentation. For this reason, the collected metadata are often incomplete, incomprehensible for outsiders or ambiguous.” The authors do not offer new tools for automation or metadata collection, but rather discuss their experiences in dealing with such issues and offer some guidance to other researchers. An interesting set of questions that the authors pose for thinking about what forms of metadata to capture is:
• What metadata would be required to replicate the experiment elsewhere?
• Is the experiment sufficiently explained, such that someone else could continue the work?
• If the recordings exhibit spurious data, is the signal flow completely reconstructable to find the cause?
• Are metadata provided which may explain variability (e.g., between subjects or recordings) in the recorded data?
• Are metadata provided which enable access to subsets of data to address specific scientific questions?
• Is the recorded data described in sufficient detail, such that an external collaborator could understand them?